

科學家一直嘗試著讓電腦變得和人類一樣,具有感知、學習與協助決策的能力。讓電腦可以理解人類語言的自然語言處理(Natural Language Processing,NLP)成為近年來十分熱門且挑戰性十足的研究領域。但是,人類語言的博大精深,有辦法教會電腦理解嗎?又該準備多少的訓練資料才夠呢?這些問題如果從語言學的觀點切入,也許能找到更多答案。
專家系統就能完成人工智慧的自然語言處理任務?
人工智慧的發展經過了兩次的寒冬,2010年掀起至今的熱潮已經是第三波的發展。在第一波的發展中,科學家嘗試將人類的思考邏輯放進電腦中,但因為還無法清楚理解人類的思考過程而失敗了;第二波的發展則以邏輯推理方法為主,科學家退了一步,不再嘗試讓電腦學會人類的思考,而是透過專家寫下規則,再讓電腦學會按照人類定義好的規則進行決策,也就是「專家系統」,但因為有太多難題無法寫成規則再度失敗;直到2010年,由於電腦的資料儲存與運算速度大幅提升,加上大數據的興起,許多演算法的概念得以實現並促成第三波的人工智慧發展。
卓騰語言科技負責人王文傑,研究所時期鑽研於語言學,也曾擔任過PyconTW講者,兼具語言學及程式設計兩種領域專業。他說,中文裡至少就有六萬多條不同的規則,早已超出人類能妥善處理的量,但在新的語言學思維範式發展下,工程師只要利用Rule-based的邏輯推理,就能完成人工智慧的自然語言處理任務。
不過,王文傑笑說,許多人都以為Rule-based已經失敗而不被使用,但這就好像當大家都拿著尖嘴鉗想要轉開螺絲,當你拿出板手,明明是最適合的工具,卻因為跟大家的工具不一樣,而備受質疑。
人類的語言變化萬千,有辦法教會電腦學完所有語言規則嗎?
在 1970 年代末期,語言學經歷了一次巨大的典範轉移 (Paradigm Shift)。王文傑解釋,在新典範提出前,語言學界認為小孩出生時,大腦是空白的,而語言能力則是經過大量的刺激學習而來;但新的典範則認為人類出生時,大腦已經有一定的結構,只要藉由少量刺激就能啟動語言能力。這也才能說明,為什麼小孩子常常有些自創的詞語出現。
卓騰語言科技基於現代語言學知識的理論,開發的產品也獲得許多醫院機關及法律界的青睞。即使這些單位沒有辦法提供龐大的訓練資料,卓騰的系統也能提供有效的成果。許多人在聽到他們主要是利用Rule-based完成NLP 的各項任務時,多半會質疑能否窮舉出所有規則?「但是,根本不用窮舉呀。」王文傑說。
他舉例:「我昨天買了一隻很會 _______ 的小狗。」這句話中,劃底線處可以放什麼字?可填入的答案可能五花八門。但如果我們問的是,畫底線處可填入什麼詞性?你的答案就被詞性的架構所收斂了。由Avram Noam Chomsky提出的X-bar Theory句法樹正好能說明這件事。在已經知道 X-bar 結構的情況下,加上固定數量的功能詞及其所帶的運算順序,不用內建字典,或是把所有可能的詞彙都先建個字典來載入,就可以解析自然語言了。
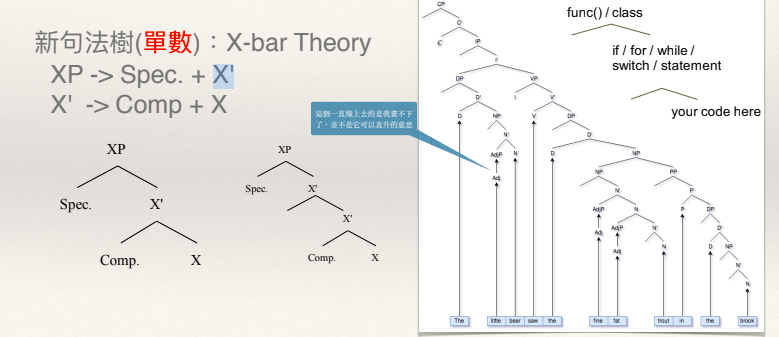
所謂的語言模型,並沒有處理到語言的問題
王文傑認為,目前將語言轉換成文字再到到語言模型的過程,是一個逐步失真的過程。他解釋,我們目前處理的過程是將語言變成沒有語氣、語調和語速的文字,接著經過斷句,前後文、語境、文法、句構也在一句句的處理過程中喪失。最後產生的語言模型,並沒有邏輯、因果與知識。
「text 不等於language,」王文傑說,世界上目前使用的 7139 種語言裡,有 4065 種語言沒有文字系統。也就是說,如何把一個想法傳遞到對方腦海中,並不一定要透過文字,但一定要透過語言形式。所以當今我們說的「train model」比較像是做出文字符號的分佈,卻沒有真正處理到語言的問題。因此,也不該叫做語言模型。
人類的語言能力主要由三大部分組成:一、輸出與輸入的能力(I/O),也就是能說能聽;二、內建的語言處理系統;三、百科知識或特定領域知識。舉例來說,當我們和某人產生以下對話:
A:「明天我要去高雄」
B:「高雄,很遠耶!」
A:「你知道高雄在哪?」
B:「高雄,很遠耶!」
你也許會覺得B的回應怪怪的?或者是不是感覺有點像是目前chatbot的回應?原因就在於B雖然具備輸入與輸出能力,也能擷取到高雄這個關鍵字,擁有前兩項語言能力,卻因為缺少了對話中的相關領域知識,而無法做出有效的回應。而相關領域知識的訓練,則需要透過機器學習技術的協助。
「Hybrid才是關鍵。」王文傑指出,要做出一個能聽懂人話的AI,並不一定得在符號邏輯和機器學習二選一才行。若能以符號邏輯的可解釋性做底,加上機器學習的百科知識補充人工智慧的經驗,再賦與其語音和文字的輸入和輸出,就能做出一個具有人類程度的AI。
去年OpenAI推出的GPT3,以其龐大的架構及驚人的運算需求引起關注,在自然語言處理領域裡,是不是非得依靠大數據才行?王文傑憂心的說,台灣的鄰居是一個一天就能產生「3.2 億篇微博貼文」的大數據產生國,如果我們的NLP技術只剩下透過數據來訓練模型這一招的話,絕對會被中國牽著走。透過現代語言學的新方法,其實可以提供 NLP 問題的公式解,先使用少量的資料,再慢慢針對需求累積語料,之後再導入機器學習等技術,是解決產業資料數量不夠多的解法。




