
關於AlphaGo打敗韓國棋王李世乭這個經典的人機大戰,想必許多人一定不陌生,而開發團隊Deepmind 又接續開發出實力更強大的AlphaZero,不僅在三天內自學了西洋棋、日本將棋及圍棋三種棋藝,更打敗全球三大棋藝AI,連AlphaGo也成為它的手下敗將。AlphaGo及AlphaZero的成功,也讓兩者所使用的強化學習,瞬間成為熱門新星。
不過,AlphaZero 雖然備受矚目,但對於許多人來說,要讀懂相關的技術論文並不容易,網路上的資料也不一定能找到公開程式碼,對於想要了解技術操作細節的人來說,實在難如登天。
本書透過圖說、實例,以及各類示意圖詳細解析深度學習、強化式學習、賽局樹等各種相關演算法,對於不懂開發環境的讀者來說,書中也針對Google所提供的免費Colab 雲端開發環境有深入說明,包括連線時間限制的處理以及 GPU/TPU 的使用說明,帶領讀者一步步打下基礎,以下是《強化式學習:打造最強 AlphaZero 通用演算法》的精彩內容摘錄整理:
AlphaZero 通殺各種棋類遊戲的關鍵 - 強化式學習
強化式學習(Reinforcement learning)是「透過代理人根據環境的狀態採取動作以獲得更多回饋值的方法」,此方法與監督式學習和非監督式學習不同,其特色在於不依靠訓練資料,只靠代理人本身以試誤法進行學習。舉例來說用 AlphaZero 選擇棋步,還有自動駕駛、自動化機器人等都是強化式學習的應用。
在強化式學習中有許多專業的術語,接下來就以「漂流到無人島的人」為例子來講解這些術語。如下表:

而強化式學習的目的如下圖:
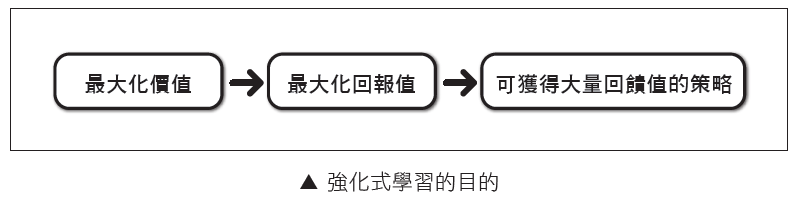
接著來講解一下強化式學習如何進行訓練,強化式學習的訓練流程是一個循環。如下圖所示:

流程如下:
步驟1 由於代理人一開始無法判斷該採取什麼動作,因此先從可採取的動作當中以隨機方式決定要採取的動作。
步驟2 代理人若能獲得回饋值,便會將這段經驗記錄下來,經驗包含了在何種狀態下採取何種動作才可獲得多少回饋值。
步驟3 根據價值衡量經驗的好壞,採取好的經驗作為下一次的策略。
步驟4 一邊保留採取隨機動作(去發掘更好的策略),一邊利用策略決定動作。
步驟5 重複步驟 2 ~步驟4 直到結束為止,尋找未來可獲得更多回饋值的策略。
以上的訓練循環稱為馬可夫決策過程 (Markov decision process),馬可夫決策過程指的是一種由當前狀態與採取的動作來決定下一個狀態的系統。其中當前狀態不受先前決策的影響,而且每個動作的結果含有不可預期的隨機性。所有的強化式學習演算法都是基於馬可夫決策過程。
策略迭代法 (Policy iteration) 與價值迭代法 (Value iteration)
接著講解強化式學習尋找策略的方法,主要分為2 種:「策略迭代法」與「價值迭代法」。示意圖如下:
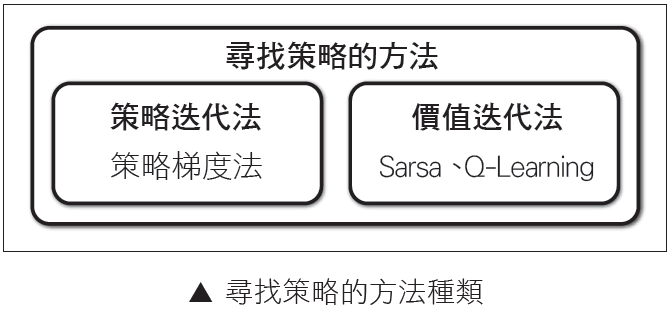
策略迭代法 (Policy iteration)
策略迭代法是一種更新策略的方法,它會在根據策略採取動作之後,強調成功時的動作,並於更新下一次的策略時盡量多採取這種動作,策略梯度法就是基於策略迭代法的演算法。
價值迭代法 (Value iteration)
價值迭代法會在每次採取某個動作時,都計算出做動作前與做動作後的價值,並且計算出兩者之間的誤差值,並將其增加至當前動作的價值,接著利用更新完的價值去決定下一個策略,Sarsa與Q-Learning 都是基於價值迭代法的演算法。
AlphaZero 的強化式學習訓練架構
強化式學習是AlphaZero強大的關鍵,透過強化式學習的訓練法,不需要準備任何一筆人類資料(只需讓AI理解棋類規則即可),讓AI自己與自己對奕,透過這種邊下棋邊學習的架構不但可以通用不同的棋類,也能產生變化多端的棋步(不會局限於人類高手的下法),進而打敗職業棋手。 AlphaZero 的架構如下圖:

利用當前的遊戲局勢(棋盤盤面)計算出價值 (Value) 與策略 (Policy),再藉由演算法預測下一步要落在棋盤的哪個位置,最後使用遊戲結果(勝負)來減少演算法的誤差,仔細觀察上圖的架構就是一個強化式學習的循環,透過多次的訓練使代理人越來越厲害。其他用到的演算法還有 ResNet、Monte Carlo tree search 以及 Boltzmann distribution。
除了 AlphaZero 以外,近年來強化式學習帶來越來越多的應用,其中兼融了深度學習的「深度強化式學習」,不但實現了人類學習的摸索過程,並且也讓 AI 了解如何做出對當下最優的決策,它是目前機器學習領域中最炙手可熱的演算法之一,也是人工智慧不可或缺的重要技術。
本文節錄自《強化式學習:打造最強 AlphaZero 通用演算法》,由旗標科技授權轉載。




